
2026/07/24
【コーディスト】100件の「生の理由」をグラフィック化!新機能「イメージクラウド」で見る消費者分析の新しいカタチ
2024/04/18

生成AIの中でも、幅広く用いられているのが「ChatGPT」です。この記事では、ChatGPTの仕組みや、ChatGPTで実行できるタスクなどについて説明していきます。
※本記事は「生成AIの基礎知識」シリーズの第2回です。初回「(1)生成AIとは」(公式web動的コンテンツ_1. 生成AIとは)を読んだ上でこちらの記事に目を通していただくとより理解が深まります。
ChatGPTは、OpenAI社によって開発された大規模言語モデル(LLM)の一種です。この技術は生成AIに分類され、文章の続きを予測するように学習されたモデルであり、例えば「日本の首都は」という入力に対して「東京」と回答する能力を持っています。ChatGPTの開発は、GPT-3というモデルからさらに進化し、GPT-3.5を経てChatGPTが登場しました。特にGPT-3.5からChatGPTへの進化は、事前学習に加えて様々な追加学習が行われ、より対話応答に特化し、人間にとって好ましい回答を提供することを目指しています。
ChatGPTの開発においては、事前学習だけでなく、ユーザーとの対話から得られるフィードバックを基に、常に学習を続けています。これにより、より自然で理解しやすい、かつ情報に富んだ回答を提供することが可能になっています。
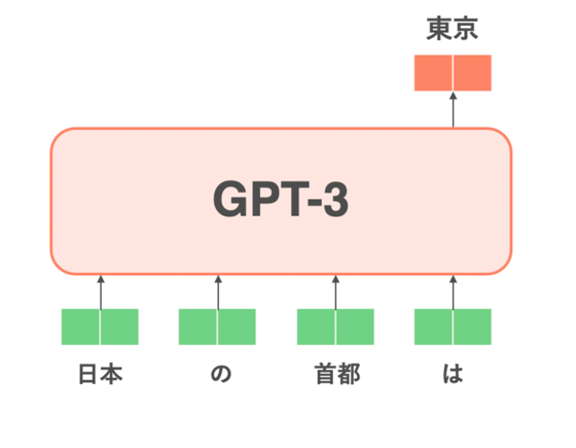
引用元: https://qiita.com/omiita/items/c355bc4c26eca2817324
ChatGPTはPre-trainedモデル(事前学習モデル)というものを採用しています。
Pre-Trainedモデルは、大量の自然言語データセットを用いて予め学習させておくことで、モデルが言語の理解と生成の能力を身につけることを指します。この学習プロセスでは、Wikipediaの記事、Web上のニュース記事、その他様々なコーパスが利用されます。これにより、モデルは広範なトピックと文脈に関する知識を獲得し、新しい入力に対しても適切な出力を生成できるようになります。
Pre-Trainedモデルの応用は、テキスト生成にとどまりません。例えば、Stable Diffusionというモデルは、テキストを基にして画像や映像を生成することができます。これは、出力側に読み込ませるデータセットを画像や映像に変えることで実現されます。この技術の進化により、ユーザーが指定したテキストの記述に基づいて、リアルタイムでビジュアルコンテンツを生成することが可能になりました。
さらに、GPT-4のような最新のモデルでは、テキストだけでなく画像も入力データとして読み込ませることができるようになりました。これにより、モデルはより複雑なデータの処理能力を持ち、テキストと画像の両方を理解し、関連付けることができます。
ChatGPTを使ったことがある方は多いと思いますが、実際にどのようなタスクが可能なのか全部知っているという方は少ないのではないでしょうか。ChatGPTで行えるタスクには次のようなものがあります。
ChatGPTの仕組みをより深く理解するために、GPT-3のモデルから進化の過程を細かくみていきましょう。
GPT-3は、OpenAIによって開発された最先端の自然言語処理モデルで、特にその巨大なスケールと汎用性で知られています。このモデルは、TransformerアーキテクチャのDecorder部分のみを使用し、そのDecorderを96個重ねることによって構成されています。このアーキテクチャにより、GPT-3は文脈を理解し、その文脈に基づいたテキスト生成を行う能力を有しています。
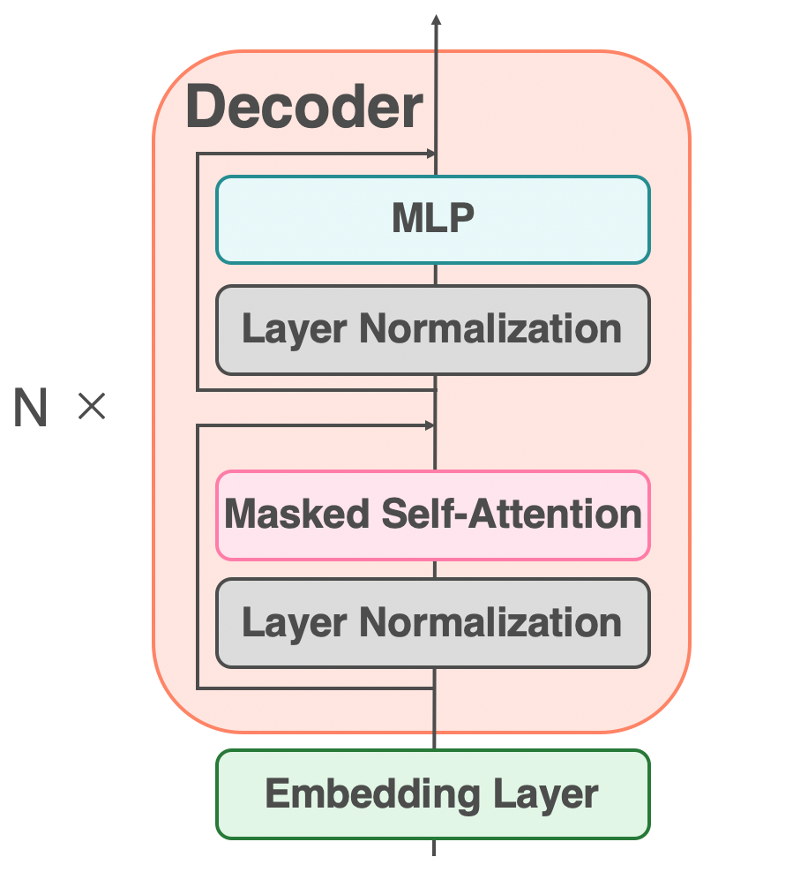
GPT-3の学習プロセスは、教師なし学習に基づいています。これは、人間によるアノテーションやラベリングが必要ない学習方法で、モデルは大量のテキストデータから直接パターンを学習します。この方法により、GPT-3は570GB以上のコーパスと、インターネット上から収集された45TBのデータを使用して学習を行い、その結果、1750億ものパラメータを持つモデルが生成されました。
GPT-3の学習プロセスは、教師なし学習に基づいています。これは、人間によるアノテーションやラベリングが必要ない学習方法で、モデルは大量のテキストデータから直接パターンを学習します。この方法により、GPT-3は570GB以上のコーパスと、インターネット上から収集された45TBのデータを使用して学習を行い、その結果、1750億ものパラメータを持つモデルが生成されました。
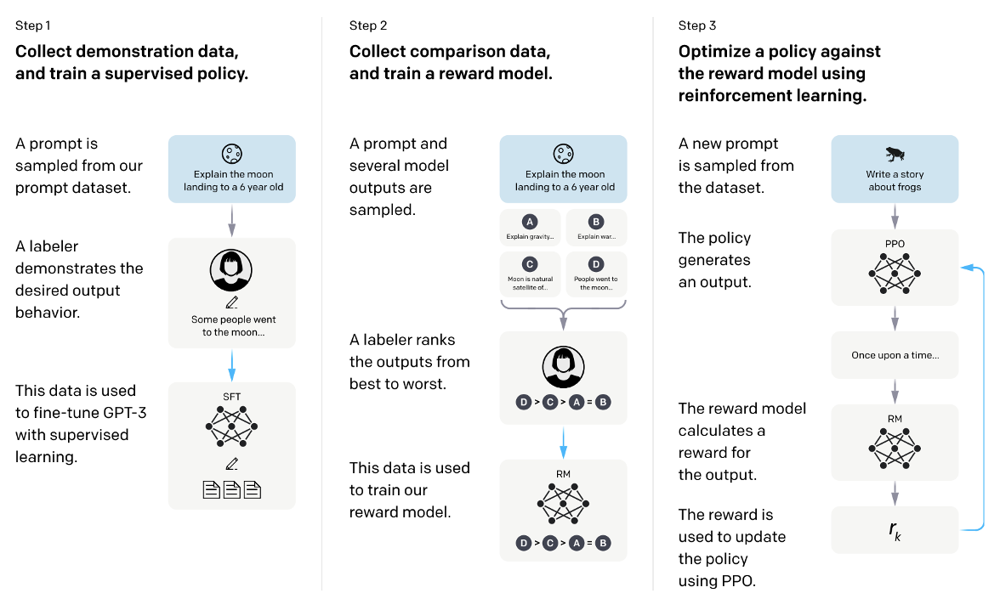
最初のステップでは、モデルを特定の応答スタイルに合わせるための教師ありファインチューニングが行われます。このプロセスでは、例えば「日本の首都はどこですか?」という入力に対して、「米国の首都はどこですか?」という不適切な応答をする代わりに、「日本の首都は東京です。」と正確に応答するよう、モデルを調整します。これを実現するために、職人が手作業で「入力」と「好ましい出力」のペアを含むデータセットを作成し、LLMにこれらのペアで再学習させます。
次に、モデルが生成したテキストの「良さ」を自動で評価するためのReward Modelが開発されます。このモデルは、生成されたテキストが真実性(Truthfulness)、無害性(Harmlessness)、有益性(Helpfulness)の3つの指標に基づいてどの程度優れているかを評価します。これにより、人間が直接評価することなく、モデルの出力の品質を高めることが可能になります。
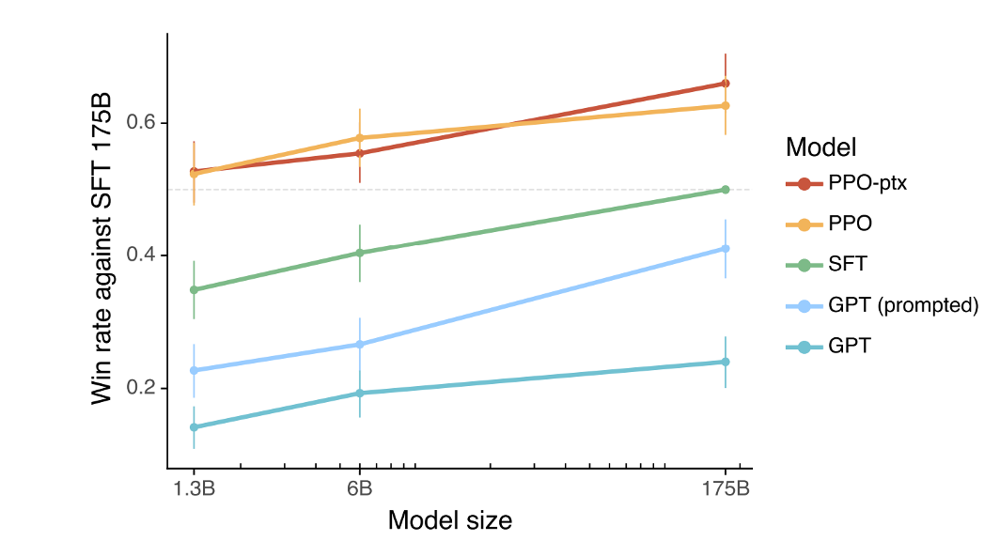
最終ステップでは、Reinforcement Learning from Human Feedback(RLHF)を用いて、SFTモデルが人間の好みに合うようにさらに調整されます。このプロセスでは、Reward Modelを最大化するようにSFTモデルを強化学習させます。結果として、13億パラメータのモデルであっても、1750億パラメータのSFTモデルよりも優れた性能を示し、従来のGPTモデルと比較しても圧倒的な改善を達成しています。
ChatGPTは、OpenAIによって開発された会話型AIで、その学習プロセスはInstructGPTとほぼ同じ方法を採用しています。しかし、ChatGPTの特徴は、その基礎となるモデルと学習データに大きな違いがある点にあります。
ChatGPTの基盤となっているのはGPT-3.5モデルです。このモデルは、テキスト生成の能力に加えて、コード生成の能力も持っています。これにより、ChatGPTは通常の会話応答だけでなく、プログラミング関連の質問に対しても適切なコードスニペットを提供することができるようになっています。
ChatGPTの学習には、一般的なテキストデータに加えて、会話データが大きな役割を果たしています。特に、「ユーザーとAIの会話」をデータセットとして含むことで、ChatGPTはより自然な会話能力を獲得しました。これは、実際の会話フローを理解し、それに基づいた応答を生成する能力を意味します。ユーザーからの質問やコメントに対して、文脈を考慮した適切な応答を行うことが可能になるため、よりリアルな会話体験が提供されます。
シリーズ第2回「ChatGPTとは」として、ChatGPTの進化の過程やその仕組みについての説明は以上です(この後に補足として「過学習とGrokking」について説明しているので、興味のある方はご覧ください)。次の第3回では、ChatGPT以外の生成系AIやLLMを紹介します。
機械学習において、モデルのパラメータ数が過剰に多い場合、一般的に過学習の問題が発生するとされています。過学習とは、モデルが学習データに過剰適合し、その結果として未知のデータに対する予測性能が低下する現象を指します。このため、長い間、パラメータ数を増やしすぎることは、モデルの性能向上には逆効果であると考えられてきました。
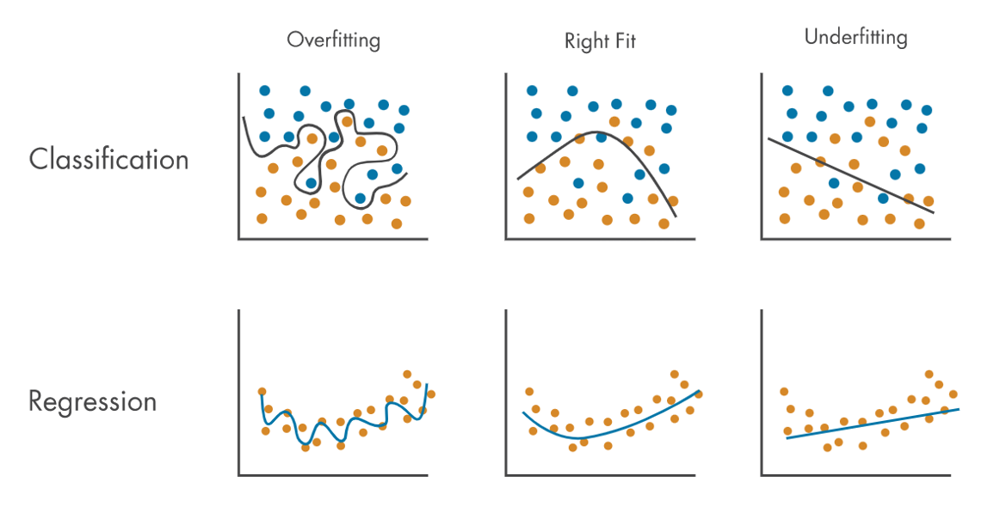
しかし、GPTやPaLMといった大規模言語モデル(LLM)は、この一般的な認識に反して、パラメータ数を大幅に増やし続けることで、予想外に高い汎化性能を示しています。これらのモデルは、膨大な量のデータを用いた学習を通じて、未知のデータに対しても高い予測精度を実現しているのです。
この現象を説明するために提案された概念が「Grokking(グロッキング)」です。Grokkingは、ネットワークが学習過程のあるポイントで突然データを「理解」し始める現象を指します。つまり、学習初期はパフォーマンスが低くても、ある時点を境に急激に性能が向上し、学習データの背後にある本質的なパターンやルールを捉えるようになるのです。この現象は、特にルールベースのタスクやパターン認識において観察されています。
Grokkingの発見は、機械学習モデルの訓練に関する我々の理解を大きく深めるものです。これにより、モデルが大量のパラメータを持つことの利点と、それがどのようにして未知のデータに対する優れた予測能力につながるのかが示唆されています。また、Grokkingは、AIの学習プロセスや知識獲得のメカニズムに新たな光を当て、今後のAI技術の発展において重要なキーワードとなる可能性があります。

この現象に関する研究はまだ初期段階にあり、Grokkingがどのような条件下で発生するのか、またどのようにしてこれを促進させることができるのかについては、今後さらなる調査と理解が求められています。
アンド・ディでは生成AIの技術を用いたマーケティングリサーチに役立つサービスを開発しています。
OpenAI社のChatGPTにも使われる大規模言語モデルのGPTを用いて、商品開発時に必要となる新しい切り口のアイデアを短時間で多数生成するAIです。

GPTモデルの活用で、アンケートの自由回答(テキスト回答)のコード化(アフターコーディング)が数分で可能です。また、集計結果はAIを用いた「まとめマップ」機能で簡単に二軸グラフに整理可能となっています。![]()
アンド・ディは「IT導入補助金2024」の支援事業者に認定され、アンケート自由回答の分類ツール「コーディスト」が同補助金の[通常枠] ITツールに認定されています。詳しくはコチラから。





