
2026/07/24
【コーディスト】100件の「生の理由」をグラフィック化!新機能「イメージクラウド」で見る消費者分析の新しいカタチ
2024/05/30

生成AIはさまざまな用途に使われており(過去記事:生成AI・LLMの活用)、業務の効率化に貢献しています。マーケティングリサーチの業務のなかで最も手間と時間がかかるインタビューの書き起こしやまとめ作業。そこで私たちは、実際のグループインタビュー内容を書き起こし~整形、修正、まとめ作業を生成AIを活用して、どれほど業務の効率化を図れるか検証してみました。実際の作業ごとに、前後編の2回に分けて具体的な検証内容とその結果を紹介します。本記事はその前編です。
今回の検証では、以前&Dで実施した「マスクに関する調査」 のインタビュー内容を使用しました。新型コロナウイルス感染症が5類に移行するのに伴い、マスクの売り上げが減少しました。そこで売り上げ減少に歯止めをかけるべく新しいマスクの開発を目指して、調査ではユーザーが「従来のマスクの機能以外にどんな機能があると装着し続けたくなるのか」を明らかにすることを目的に複数人へのインタビューを行いました。
インタビューは、マスクの利用に関する「実態把握」と、新しいマスクの4つのコンセプトに対する「評価(コンセプト評価)」の2部で構成されています。

前半の実験では、以下の3つの工程に生成AIを使用しました。
具体的には、音声の書き起こし・話者判定を行う・フィラー(「あのー」「ええと」などのつなぎの言葉)の削除及び改行・話者判定の修正などを生成AIに行わせました。

また、インタビュー内容を収録した音声データからの書き起こしは次のような流れで行いました。
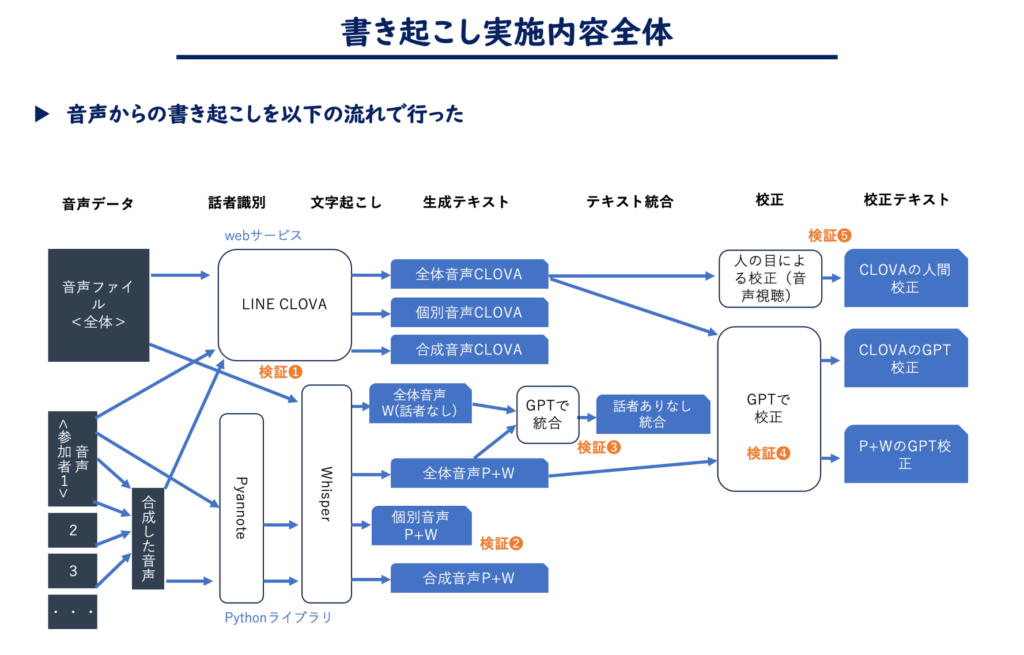
今回は次のようなツールを使用しました。
CLOVA Note: LINEが提供するこのWebサービスは、書き起こしと話者分離機能を持っています。 特に、解析スピードと使いやすいUIで高く評価されています。
Notta: Notta株式会社が提供するWebサービスで、同様に書き起こしと話者分離機能を備えています。ただし、当社のテストでは書き起こしの精度が期待に満たなかったため、この記事では利用していません。
Whisper: OpenAI社によって公開された書き起こしのモデルです。Pythonで使用され、多言語に対応しています。
Pyannote: こちらもPythonで利用可能なオープンソースの話者識別モデルです。上記Whisperと組み合わせて使われることが多いです。
聞き取りデータは2グループ分あり、各グループ1時間40分です。このデータの音声書き起こしの精度を比較するために、CLOVAとWhisperの2つを使用して検証しました。CLOVAは約3分で処理を完了し、Whisperはmediumの設定で処理に約40分を要しました。結果としてCLOVAの方が性能が高いことが明らかになりました。
CLOVAは、話者分離と書き起こしの両方で人間が理解できるレベルの精度になっています。ただし、文末での不正確な内容が残りやすく、フィラー言葉をあまり省略しないため、読点が多くなりがちです。また、話者の人数の認識には不正確さが見られました。

CLOVA書き起こし内容より抜粋
一方、WhisperとPyannote(W+P)を組み合わせたモデルでは、理解困難な箇所が多く、活用しにくい結果になりました。特に、「んんんんんんんんん」といった不自然な連続音が発生することや、1人の話者の発言が重複する問題がありました。これらの点は、使用するにあたって考慮が必要です。
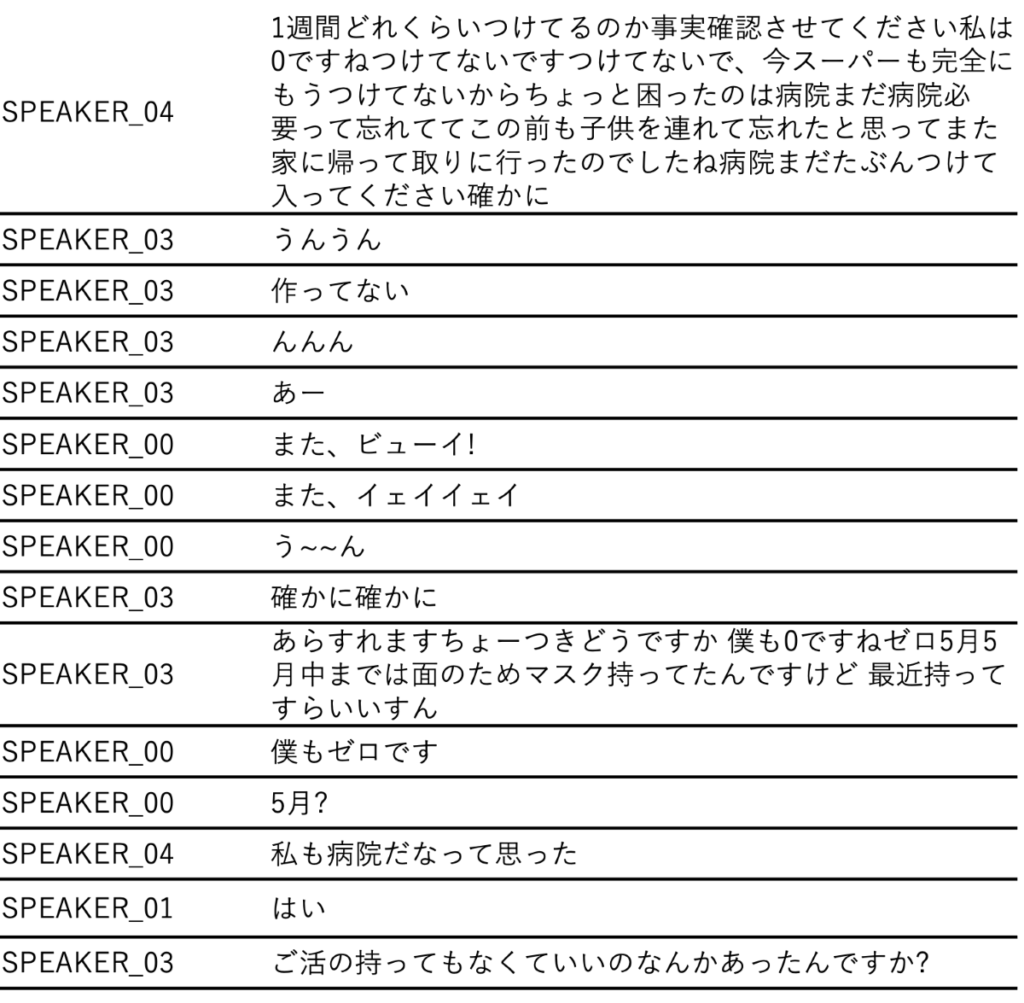
Whisper + Pyannoteでの書き起こし内容より抜粋
司会者と参加者Aの個別マイクを用いて書き起こしを試みました。その結果、個別マイク以外の音声も多く拾ってしまうという問題が発生しました。個別マイクで捉えた音声は全体の音声と同等の精度で書き起こされましたが、それ以外の音声に関しては精度が著しく低下し、一部が抜け落ちてしまいました。これは、個別マイクによる話者判別が難しく、異なる音声が混ざりやすい環境にあるためです。
個別マイクの対象となる発言は音量が大きく、聞き取りやすいという特性があります。この特性を利用し、個別マイクで捉えた音声を合成することで、全体の音声をクリアにするというアイデアを検証しました。オーディオ編集ソフトを使用し、個々の音声のタイミングを正確に合わせてミックスすることで、一つの音声ファイルを作成しました。
実際に耳で聴いてみた結果、音声の重なりによるわずかな違和感は感じられましたが、各話者の声ははっきりと聞き分けることができました。
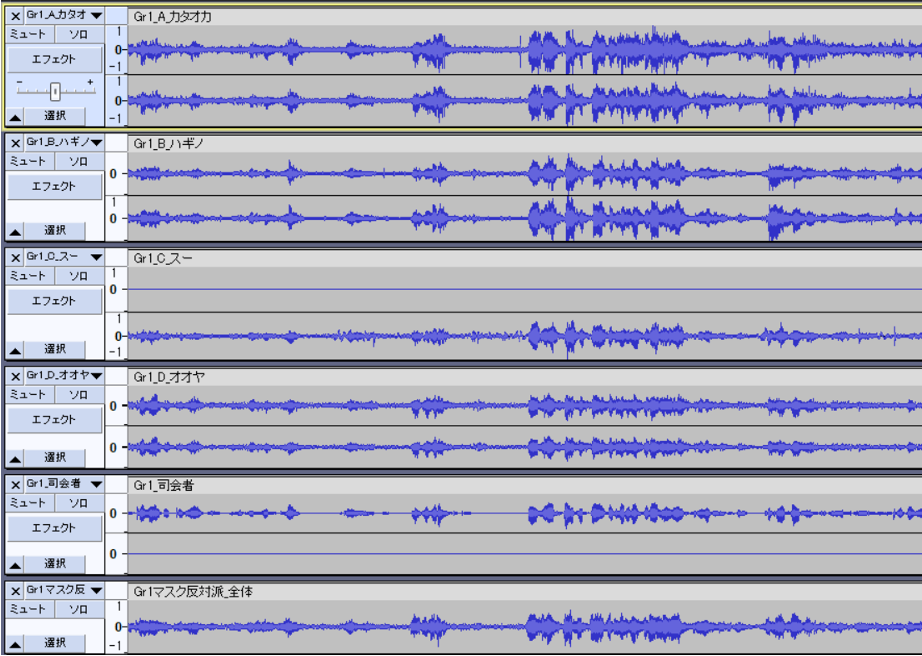
しかし、実際には合成音声での精度向上は見られませんでした。
CLOVAを用いて合成音声の書き起こしを行った場合は、書き起こされる内容がかなり絞られてしまいました。W+Pの場合はより内容が不鮮明になってしまいました。

<画像>
音声認識の精度向上に向けた新たな試みとして、Whisperのみでの書き起こし結果とPyannoteによる分析結果を、GPTを使って融合させるアプローチを検証しました。
まず、Whisper単体の書き起こし精度は高いものの、Pyannoteと併用したことの弊害が大きく、精度が低くなってしまったという仮説を立てました。そこで、GPT-4を用いて両方のテキストデータを組み合わせることで、より品質の高いテキストを生成しました。
この方法によりテキストの品質向上がかなり見られました。具体的には、GPTを用いたことで文脈が整理され、意味のある内容に改善される部分もありました。一方で、CLOVAによる出力と比べて話者判別の精度はやや劣っていました。
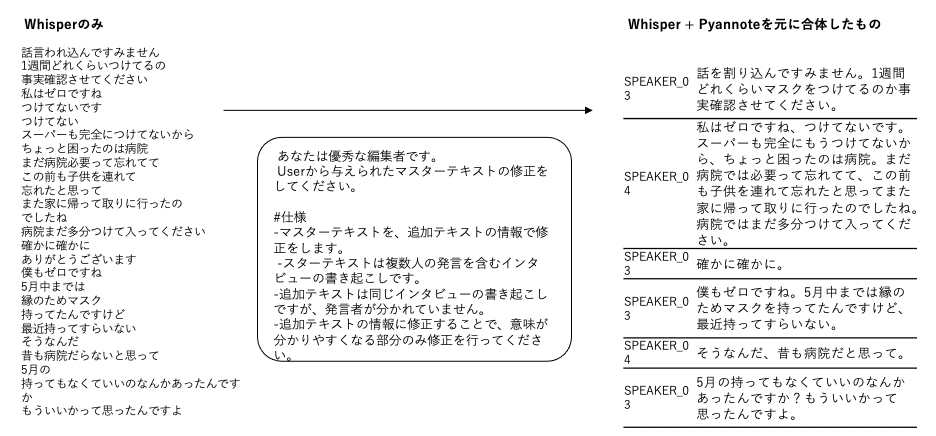
テキスト校正に際して、GPT-4に対しては次のような指示を与えました。
指示
仕様
CLOVAによる出力内容はGPT-4の校正により若干向上しましたが、完全には理解しづらい言葉や、文末に不自然に残る「も、」などの文節は修正されませんでした。
一方で、もともとほぼ読めないレベルだったWhisper+Pyannote(P+W)の出力は、GPT-4の介入によってかなり読みやすくなりました。これは、GPT-4が文脈を考慮した上での修正を加えることができるためです。しかし、GPT-4による校正はコントロールが難しく、予期せぬ部分が大幅に削除されることがあり、場合によっては記事の重要なセクションが丸ごとなくなってしまう時もあります。

AIを使った場合と比較するために、CLOVAを利用した音声書き起こしの結果を基に、人間が直接聞き取りながら修正を行ってみました。人間の場合は音声のみから話者を特定することは難しく、司会者のみ識別することができました。校正作業には相当の時間を要し、特に初めてこの作業を行う人にとっては、2グループ×1時間40分の音声を修正するのに約12時間を費やしました。これは元の音声の3~4倍の時間に相当します。
一般的に、音声のテープ起こし作業には原音声の7~8倍の時間がかかるとされていますが、CLOVAを使用した場合、時間を半分程度に短縮することが可能です。ただし、プロのインタビュー書記者はインタビューが完了すると同時に書き起こしを完了させることができるため、CLOVAを用いる方法が万人にとって効率的とは限りません。
この検証から、AIによる書き起こしと人間の校正を組み合わせることで、ある程度の省力化は見込めるものの、作業の性質やスキルレベルによって最適な方法は異なることが示されました。

本検証では、「Empath」という、音声の物理的特徴量から気分の状態を判断するプログラムを使用しました。Empathは、テキストの内容を分析に用いるのではなく、独自のアルゴリズムを通じて音声等から感情の状態を判定します。このプログラムは、最大で5秒間の音声を分析し、その結果を提供します。
無料のテスト期間を利用し、数分間の音声データの一部のみ解析してみました。Empathは、悲しみ、喜び、怒りなどの感情を数値化し、各感情の最大値を50としています。以下がその結果です。
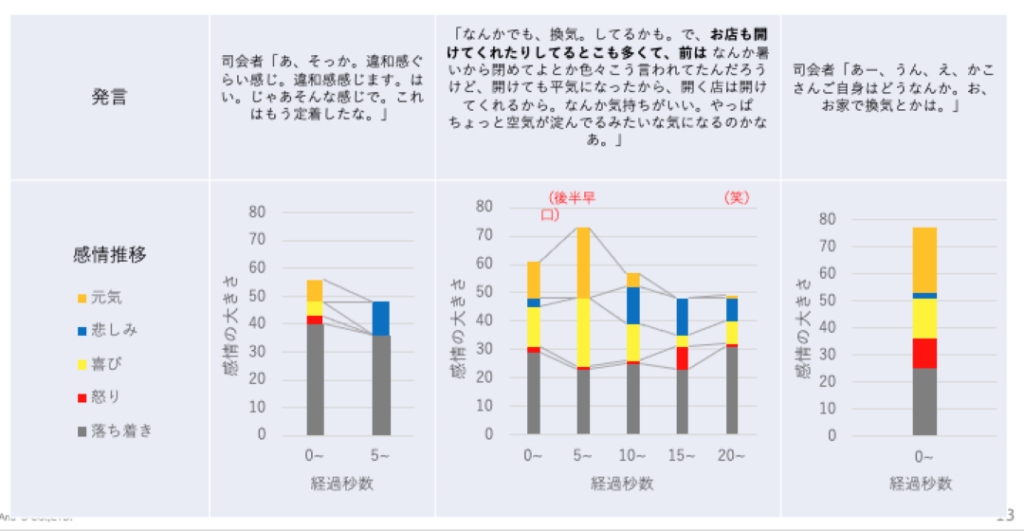
果を見てみると、ある程度あっているような気もします。が、どの感情がどの言葉と対応しているかはわかりにくいです。
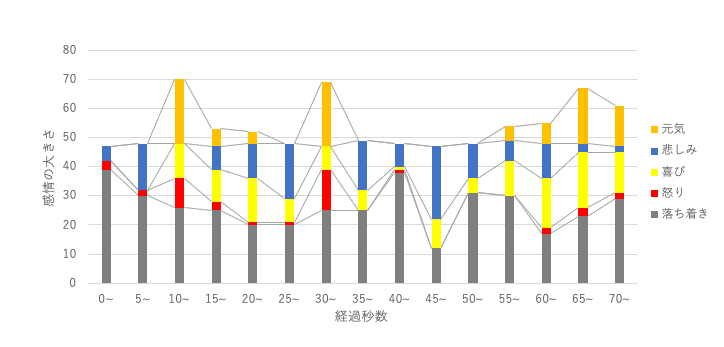
以下は、全体の話の流れをEmpathで分析した際の結果です。全体を評価して、どの部分で話が盛り上がっているか見られるのは良い機能かもしれません。
1. 音声認識と話者分類のモデル精度
→CLOVA Noteが比較的高い性能を持っていましたが、Whisper+Pyannoteのアウトプット内容はそのままでは利用が難しいと明らかになりました。
2. 個別マイクを使用して音声取得の精度を向上させる方法
→各音声の書き起こしは、個別音声がかなりのレベルで取れていないと難しいとわかりました。また、音声の合成による精度向上は見られませんでした。
3. 話者分離なしの音声認識の精度を利用する方法
→Whisperの結果のみを利用して精度を向上させることが有効であることが示されました。
4. GPTモデルを用いたテキスト校正の効果
→GPTモデルを利用することで読みにくい状態からも文章として生成する力はありますが、読みにくい部分や抜け落ちが散見されます。
5. 人間の目での修正をした場合の省力化
→修正にかかる時間を半分程度に節約することができますが、話者判別が難しいなどの課題があります。
6. 音声からの感情判定の精度
→感覚的にはまずまずの結果が得られました。
次回の検証では、インタビューフローの内容ごとの分割・テーマごとの要約・要約を元にしたまとめ作成に生成AIを活用してみます。






